
Ensenso 3D operation How does projected texture stereo vision work?
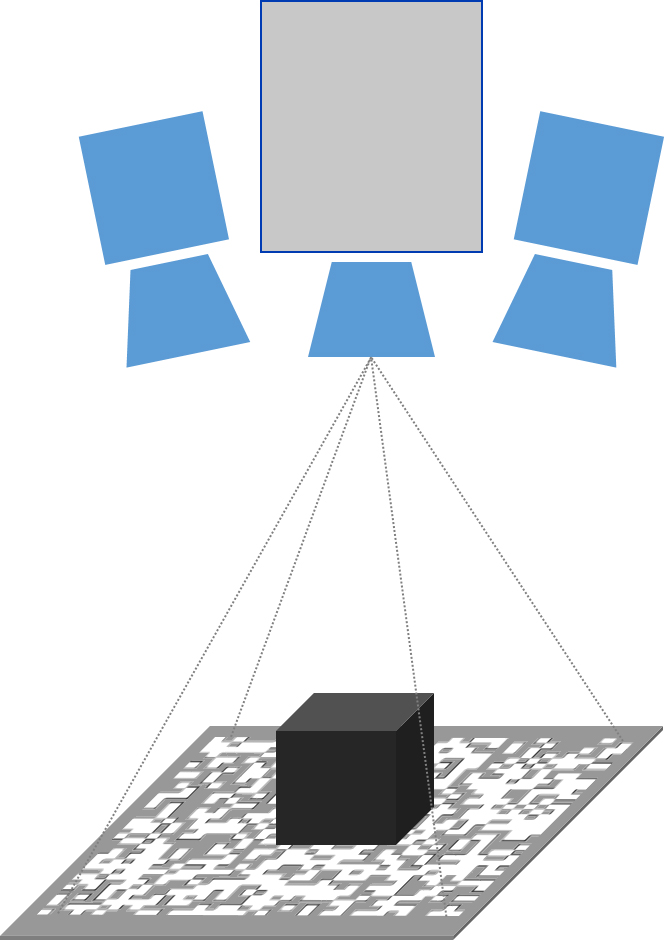
Stereo vision
Ensenso Stereo Vision cameras imitates the human vision. Two cameras acquire images from the same scene from two different positions.

Although the cameras see the same scene content, there are different object positions according to the cameras projection rays. Special matching algorithms compare the two images, search for corresponding points and visualize all point displacements in a Disparity Map.
Knowing the distance and viewing angle of the cameras in addition to the lens focal length, the Ensenso software converts these disparities in length units using the triangulation principle. So the 3D coordinates of each image pixel could be determined. The result is a 3D point cloud, which is the foundation for further applications based on 3D object information.

The matching process during the image comparison is based on contrast- and brightness graduations of the sensor pixels. So the Stereo Vision quality directly depends on the scene’s light condition and object surface textures. Finding and calculating coordinates of corresponding points on less textured or reflecting surfaces is very difficult. The disparity cannot be uniquely determined. The result is an incomplete depth information of the scene.
Ensenso cameras improve the classic Stereo Vision principle with an additional pattern projection to achieve a higher quality depth information and more precise measurement results. As a consequence Stereo Vision can be used in a wider range of applications.
Pattern projector
A light-intensive projector produces a high-contrast texture on the object surface by using a pattern mask, even under difficult light conditions. The projected texture supplements the weak or non-existent object surface structure.
Therefore this principle is also called “Projected Texture Stereo Vision”. The result is a more detailed disparity map and a more complete and homogeneous depth information of the scene.

FlexView
The FlexView technology can further improve the detail level of the disparity map of static scenes. The position of the pattern mask in the projection rays can be translated in small steps by a mechanical system using a piezoelectric actuator. The result is a varying texture on the object surface. Acquiring multiple image pairs with different textures of the same object scene produce a lot more image points. The resolution increases. The matching algorithm calculates significantly improved disparity maps by using all captured image pairs.
As a consequence of the texture displacement which produces additional structure information on glossy, dark or reflecting surfaces, the resolution and also the robustness of the resulting data will increase. A lot of processing algorithms benefit from the higher resolution and the lower noise. FlexView reduces post processing steps of the point cloud and further 3D processing time.
Image acquisition with FlexView, which provides the necessary details for applications e.g. in quality inspection, such as measurement tasks or for counting gear teeth.
Image acquisition without FlexView with a high data rate, which is used for applications such as bin picking or presence detections.
Comparison of FlexView1, 2 and single shot data
Ensenso offers cameras with and without FlexView technology. Each solution is optimized and adapted to particular applications. The object movement plays a decisive role in this respect.
Cameras without FlexView and respectively with FlexView1 technology produce a high-contrast texture by using a random dot-pattern. It allows calculating depth information very fast even with only one image pair. Both camera variants are equally suitable for application with moving objects.
Using static objects FlexView1 cameras additionally benefit from algorithms, which produce a higher resolution combining multiple image pairs acquired with translated dot-pattern. With only 3 to 5 image pairs, the X-, Y- and Z-resolution can be doubled. But with each additional image pair the acquisition and processing will increase. With approximately 8 image pairs the resulting quality doesn’t increase any further with FlexView1.
Cameras implementing FlexView2 technology use a specially designed pattern-mask with appropriate algorithms able to double the resolution in X-, Y- and Z-direction of static objects compared with FlexView1.
Constraints: Due to the special pattern, the optimization is effective only with at least 5 image pairs.

Random dot-pattern used as projector mask for cameras without FlexView respectively with FlexView 1. Optimized for single shot data.

Additional brightness gradients in the FlexView 2 pattern support the appropriate algorithms by calculating objects depth information with at least 5 image pairs. These brightness gradients reduce the pattern’s effectiveness in single shot data.
Without FlexView
(Single-shot-data)
Suitable for:
fast applications and moving objects
Very fast image acquisition and processing by using only one image pair
Usable for moving and still standing objects
Projector pattern optimized for single shot data
FlexView1 and FlexView2
(in multi-acquisition mode)
Suitable for:
applications with stationary standing objects and the need for higher accuracy results
Highly improved resolution and quality of depth information on static scenes
Finer object details and contours
More robust to dark, reflective, less textured surfaces
Only suitable for stationary standing objects
Longer acquisition and processing time
Embedded 3D-Vision
The integrated data processing of the new Ensenso XR series optimally supports the use of FlexView 2 technology with up to 16 image pairs, especially in static scenes. The computationally intensive tasks of the Ensenso stereo processing are completely executed on the camera with hardware acceleration. This allows image acquisition and processing to work hand-in-hand without waiting times due to network transfer. The combination of FlexView 2 technology and the high parallelization of the stereo processing in the camera's FPGA enables the generation of high-resolution point clouds of stationary objects with very high frame rates. The quality of the generated 3D data increases with the image resolution and each image pair, without the additional time delay caused by data transmission to a host PC.